.jpg.21f59ffd286dc62a0a112ccc14771f40.jpg)

or1k
-
Posts
164 -
Joined
-
Last visited
-
Days Won
1
Everything posted by or1k
-

-
Two serious problems were discovered (https://lore.kernel.org/lkml/v6czqjwdsso2hy6be7qeu4mqxsx4oydq6shavws4k7sexshcrp@np4inrse4e4p/T/) and fixed (https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=99bd3cb0d12e85d5114425353552121ec8f93adc) in the bcachefs file system, which has been part of the Linux kernel since 6.7, in preparation for the 6.8 kernel release (the fixes will be part of the 6.8-rc4 release). - The first issue is related to incorrect locking when working with directories, so that when deleting non-existent subvolumes, the first deletion attempt could result in an error and the second attempt could hang due to leaving an unreleased lock. - In the second case, a race condition occurred, which could lead to premature thread termination in the kernel when closing files. The problems are present in all versions of bcachefs since the original pull request in kernel 6.7. Both problems are considered serious enough to backport the proposed patch to the stable 6.7 kernel branch.
-
 The company has published (https://opensource.apple.com/releases/) source code (https://github.com/apple-oss-distributions/distribution-macOS/tree/macos-143) of low-level system components of macOS 14.3 (Sonoma) that use (https://www.opennet.ru/opennews/art.shtml?num=60563) free software, including Darwin components and other non-GUI components, programs and libraries. A total of 172 source packages have been published. Compared to macOS 13, the gnudiff and libstdcxx packages have been removed. At the same time, open source components used in the iOS 17.3 mobile platform were published (https://github.com/apple-oss-distributions/distribution-iOS/releases/tag/ios-173). The publication includes two packages - WebKit and libiconv.
The company has published (https://opensource.apple.com/releases/) source code (https://github.com/apple-oss-distributions/distribution-macOS/tree/macos-143) of low-level system components of macOS 14.3 (Sonoma) that use (https://www.opennet.ru/opennews/art.shtml?num=60563) free software, including Darwin components and other non-GUI components, programs and libraries. A total of 172 source packages have been published. Compared to macOS 13, the gnudiff and libstdcxx packages have been removed. At the same time, open source components used in the iOS 17.3 mobile platform were published (https://github.com/apple-oss-distributions/distribution-iOS/releases/tag/ios-173). The publication includes two packages - WebKit and libiconv. -
In my country, what country - I won't say what country - they passed a bill that blocks people's bank accounts. Completely. No money transactions. Accordingly, how can we continue to work with our clients? Option one. (Bad). The client sends cash by mail in an envelope. Why bad? The post office will steal the package. The post office will block the package. Too many risks. Option two. (+/- option). The customer buys a cheap book. He puts 1 bill on each page. Ends up sending the cash in the book. There are risks too, but less. First of all, books are very rarely inspected in post offices. Even if they check the parcel, they'll see the book. Of course, if they open the book, and there is money - then you are unlucky and you are sitting without a paycheck. Who should pay for the book and the delivery? It's negotiable. In 80% of cases, the person who did the work will pay for both the book and the delivery. However, it's undeniable - the most reliable option is to get cash directly from hand to hand. Therefore, it is good to have someone trusted by the bosses and the company who can come to you and hand over the cash. It can be a person who is not far from you, in another city or province. However, distance is not the main factor. There may be a person who is constantly on business trips and travels from city to city. At a bus stop in your city, he or she can hand the money to you. If you have any other ideas for getting paid in an envelope - write.
-
Cloudflare announced the release of Foundations: a powerful Rust library for building distributed, production-grade systems. Initially developed as part of the Oxy proxy framework, Foundations has evolved into a versatile library designed to simplify the complexities of deploying and managing services at scale. This open-source project, now available on GitHub, empowers engineers to focus on core business logic rather than getting bogged down by intricate production operation setups. Foundations address the challenges that emerge when transitioning from a simple local prototype to a full-fledged service in a global production environment. The key differentiators include observability, configuration, and security. Foundations, rooted in Cloudflare's experience in developing numerous services, serve as a comprehensive solution to these critical distinctions. The key principles of the development of Foundations are: High Modularity: Foundations is designed with high modularity, allowing teams to adopt individual components at their own pace, facilitating a smooth transition for existing services. API Ergonomics: Prioritizing user-friendly interactions, Foundations leverages Rust's procedural macros to offer an intuitive and well-documented API, minimizing friction in usage. Simplified Setup and Configuration: Foundations aims to be 'plug and play,' providing essential functions that work immediately while offering adjustable settings for fine-tuning. The focus on ease of setup is tailored for specific, production-tested environments. The components that Foundations offers are necessary for most service needs: Logging: Records arbitrary textual information, aiding in documenting operational errors. Tracing: Offers detailed timing breakdowns of service components for identifying performance bottlenecks. Metrics: Provides quantitative data points crucial for monitoring the overall health and performance of the system. Foundations' logging API builds upon tokio/tracing and slog, introducing enhancements to handle hierarchical logging contextual information seamlessly. Leveraging future instrumentation machinery, Foundations enables implicit passing of the current logger for each request, streamlining the process and preventing obstruction of business logic. Tracing in Foundations is similar to tokio/tracing but differs for: Simplified API: Foundations streamlines the setup process for tracing, adopting a minimalistic approach. Enhanced Trace Sampling Flexibility: Allows selective override of sampling ratios in specific code branches for detailed performance investigations. Distributed Trace Stitching: Supports integration of trace data from multiple services, contributing to a comprehensive view of the entire pipeline. Trace Forking Capability: Addresses challenges in long-lasting connections with numerous multiplexed requests, simplifying analysis and improving performance. For metrics, Foundations incorporates the official Prometheus Rust client library. It offers enhancements for ease of use and introduces a procedural macro for a simplified definition of new metrics with typed labels. An example is the following snippet: use foundations::telemetry::metrics::{metrics, Counter, Gauge}; use std::sync::Arc; #[metrics] pub(crate) mod http_server { /// Number of active client connections. pub fn active_connections(endpoint_name: &Arc<String>) -> Gauge; /// Number of failed client connections. pub fn failed_connections_total(endpoint_name: &Arc<String>) -> Counter; /// Number of HTTP requests. pub fn requests_total(endpoint_name: &Arc<String>) -> Counter; /// Number of failed requests. pub fn requests_failed_total(endpoint_name: &Arc<String>, status_code: u16) -> Counter; } The memory profiling is implemented enabling jemalloc memory allocation, with a straightforward and safe Rust API for accessible integration. Foundations is also equipped with a built-in, customizable telemetry server endpoint. This server automates functions such as health checks, metric collection, and memory profiling. In Foundations, security is assured by robust and ergonomic API for seccomp, a Linux kernel feature for syscall sandboxing, adding a layer of security against threats. Foundations provides a simple way to allow syscalls, also allowing compositions of multiple lists: use foundations::security::common_syscall_allow_lists::{ASYNC, NET_SOCKET_API, SERVICE_BASICS}; use foundations::security::{allow_list, enable_syscall_sandboxing, ViolationAction}; allow_list! { static ALLOWED = [ ..SERVICE_BASICS, ..ASYNC, ..NET_SOCKET_API ] } enable_syscall_sandboxing(ViolationAction::KillProcess, &ALLOWED) The Cloudflare team says: and they believe can be useful to the community, this is why they open sourced the Foundations library.
-
GitLab CI/CD is a DevOps automation tool that helps software developers automate the steps involved in building, testing, and deploying code, as well as improving productivity, security, and quality in during the software development lifecycle. In this review, we will break down GitLab CI/CD in terms of its features, pricing, advantages, and disadvantages to help determine if it is the right tool for your development needs. And, to give you options when shopping around, we will also reveal some of the best GitLab CI/CD alternatives. GitLab started in 2011 as an open-source project to help a team of programmers collaborate. Since that time, it has grown into a full-fledged DevSecOps platform with over 30 million registered users that helps developers deliver secure and compliant software faster and more efficiently. GitLab CI/CD falls under the massive GitLab umbrella and is one of the DevSecOps platform’s top sets of features that was eventually added years after the initial company launch. Features of GitLab CI/CD GitLab CI/CD has several features to help developers automate their software development life cycle. Here are some of the CI/CD tools’ highlights that you can leverage to make your SDLC on-demand and repeatable without the need for a ton of manual input: Auto DevOps. ChatOps. Browser performance testing. Load performance testing. Connect to external repositories. Interactive web terminals. Review apps. Unit test reports. Docker containers. Feature flags. Code quality. License compliance. Container scanning. Dependency scanning. Security test reports. Auto DevOps is GitLab’s collection of pre-configured features and integrations that combine to support software delivery. The feature first detects your programming language. Next, it creates and runs default pipelines via CI/CD templates to help build and test your application. From there, you can configure deployments to move from staging to production and configure Review Apps to preview each branch’s changes. ChatOps lets developers interact with CI/CD jobs through Slack and similar chat services. With ChatOps, programmers can run CI/CD jobs, see job output, collaborate with team members, and more all in one place. GitLab CI/CD has browser performance testing and load performance testing. The former can help developers quickly see how pending code changes will impact browser performance, while the latter can show how upcoming code changes will affect server performance. There is no need to move your entire project to GitLab. Connect to an external repository like GitHub, Bitbucket Cloud, etc., and you can enjoy the benefits of GitLab CI/CD without the fuss. The CI/CD tool’s features continue with interactive web terminals that you can open to debug running jobs, plus Review Apps, a collaborative tool that supplies an environment to preview code changes. GitLab CI/CD has unit test reports that highlight test failures on merge requests. It lets you run CI/CD jobs in separate Docker containers and has risk-reducing feature flags for deploying new application features to production in small batches. Its Code Quality feature analyzes code quality and complexity to simplify code and minimize maintenance, and its License Compliance feature scans project dependencies for their licenses. Rounding out GitLab CI/CD’s features are container and dependency scanning that check for known vulnerabilities and security test reports that check for vulnerabilities like data leaks, DoS attacks, and unauthorized access. GitLab CI/CD pricing GitLab has three pricing tiers that software developers can choose from. It also has a free 30-day trial for its top offering – the Ultimate plan – with no credit card required. It is worth noting that GitLab is a comprehensive DevSecOps platform. GitLab’s CI/CD tool makes up just part of a massive set of features, and it is not until you get into the Premium plan that advanced CI/CD functionality becomes available. Here are the pricing tiers for GitLab: Free: No cost with limited features. Premium: $24 per user, per month. Billed annually at $285.36. Ultimate: $99 per user, per month. Billed annually at $1,188. GitLab’s Free plan supplies all the basics for individual developers, such as five users per namespace, 5GB of storage, 10GB transfer per month, and 400 monthly units of compute. GitLab Premium is for development teams looking to boost team coordination and productivity. It offers advanced CI/CD via external templates, merge trains, CI/CD for external repo, and a pipelines dashboard. Other GitLab Premium highlights include Enterprise Agile planning, code suggestions, 50 GB of storage, 100 GB transfer per month, and 10,000 monthly units of compute. GitLab Ultimate offers organization-wide planning, compliance, and security. Pay $99 per user, per month, and you can receive 250 GB of storage, 500GB transfer per month, 50,000 monthly units of compute, vulnerability management, container scanning, static application security testing, and more. All the plans, including Free, allow you to bring your own GitLab CI runners. You can learn more about GitLab’s pricing here. Advantages of GitLab CI/CD GitLab CI/CD has several advantages that make it an attractive choice for developers seeking an automation tool to boost productivity and efficiency: Flexibility. Security. Code quality. Easy to use. The biggest advantage of GitLab CI/CD is its flexibility. The CI/CD tool works with all the top languages and frameworks and can be tweaked to fit your development team’s unique needs. GitLab CI/CD is also secure thanks to its container and dependency scanning features, security test reports, etc. Developer code quality can improve with GitLab CI/CD too. The Code Quality feature ensures your code is concise, readable, and as maintenance-free as possible, and the tool helps coders snag bugs and other issues before moving to production. And, while GitLab CI/CD has plenty of features, one of the most important is that the tool is easy to use. Disadvantages of GitLab CI/CD Despite its bevvy of features and advantages, GitLab does have a few disadvantages worth mentioning: Sluggish interface. Scalability. Complexity with larger projects. Price. Where does GitLab CI/CD need improvement? Some say that the interface, while intuitive, can sometimes seem a bit sluggish. Scaling can be difficult for development teams with larger projects, and while primarily user-friendly, GitLab CI/CD can become complex for more extensive projects too. And if you are looking to unlock GitLab CI/CD’s top features, you will have to upgrade to one of its paid plans, which may bust the budget of smaller teams. Alternatives to GitLab CI/CD GitLab CI/CD has some competition in the CI/CD tool market. Here are some of the top GitLab CI/CD alternatives. Jenkins If your development team does not mind a complex setup, open-source Jenkins may be your ideal GitLab CI/CD alternative. Besides being free and giving you access to over 1,800 plugins, Jenkins is completely customizable. You can learn about Jenkins and its features in our Jenkins CI/CD Tool Review. GitHub Actions If you prefer GitHub over GitLab, then GitHub Actions is a no-brainer. The GitLab CI/CD alternative is a more affordable option that is ideal for developers looking to build, test, and deploy directly from GitHub. GitHub Actions has a free plan, and its Team plan starts at $3.67 per user, per month. See what GitHub Actions has to offer here. Travis CI Travis CI is a GitLab CI/CD alternative that is easy to set up and maintain if you choose one of its cloud-hosted options that start at $64 per month. Travis CI also has a self-hosted Enterprise option for teams looking for top-notch performance, scalability, and versatility. Its multi-language build matrix supports over 30 coding languages, and the CI/CD tool requires one-third less code than its competition. Learn more about Travis CI here. Final thoughts on GitLab CI/CD While GitLab CI/CD may not be the only tool of its kind, it is a solid choice for development teams seeking automation through a user-friendly, flexible, and secure solution.
-
Data continues to be the backbone of any modern organization. But with the exponential growth in data volume coupled with the intricacies of cloud infrastructures, organizations have migrated toward cloud-hosted databases in favor of their flexibility and scalability. However, this transition has ushered in a new set of challenges, primarily revolving around the concerns over security and compliance, and demanded a shift in how organizations strategize, implement and enforce access controls. The conventional methods of providing “read only” access and provisioning additional permissions became too slow, and giving admin access posed too great of a security risk. As a result, just-in-time granular database access is no longer an option. For part one of our how-to series on access management for the most commonly used databases in today’s cloud environments, we’ll do a deep dive into MySQL, including a cheat sheet to all MySQL access commands. Why Controlling Access to MySQL Is Important Access control in MySQL is not merely a security measure, it’s part of effective database management. Data privacy: Ensure that sensitive data remains visible and usable to authorized users, aligning with data protection regulations around personal identifiable information (PII). Data security: Limit user privileges to mitigate the risk of malicious attacks like SQL injection attacks and privilege escalation. Prevention of unauthorized modifications: Reduce the possibility of accidentally running write/delete commands on the wrong database. Resource management: Avoid unexpected overloads caused by unauthorized users running resource-intensive queries. Compliance requirements: Adhere to regulatory compliance mandating stringent access controls and visibility into access history. Business continuity: Ensure business continuity by mitigating incidents that could disrupt database operations. What to Consider When Controlling Access to MySQL When establishing access controls in MySQL, various factors come into play. Considerations include the need for different permission levels, managing user roles and ensuring compliance with data protection regulations. Striking the right balance between providing access for legitimate tasks and preventing unauthorized activities is crucial for a seamless end-user experience while maximizing security. Permission granularity: Define permissions at a granular level (databases vs. tables), considering the principle of least privilege. Ensuring that users only have access to the specific resources and actions necessary for their roles means less manual provisioning of access. User roles and responsibilities: Clearly define user roles based on not only job functions but also responsibilities to prevent the need for constantly updating new user permissions one by one. Compliance and auditing: Implement robust, yet usable, auditing mechanisms to help track user activities and detect any unauthorized access promptly. Regularly audit access controls to ensure compliance with internal policies and external regulations. Dynamic access management: Consider solutions that offer dynamic, just-in-time access workflows for MySQL, like Apono. This ensures that users have access only when needed, reducing the window of vulnerability. A MySQL Cheat Sheet for All Commands to Control Access Here’s a quick reference cheat sheet for MySQL access control commands: Create a new user. CREATE USER 'username'@'localhost' IDENTIFIED BY 'password'; Grant privileges to a user. GRANT SELECT, INSERT, UPDATE ON database.table TO 'username'@'localhost'; Revoke privileges from a user. REVOKE DELETE ON database.* FROM 'username'@'localhost'; Create a new role. CREATE ROLE 'rolename'; Grant a role to a user. GRANT 'rolename' TO 'username'@'localhost'; Conclusion The access control capabilities of MySQL aren’t comprehensive enough to effectively address all aspects of security, privacy and compliance. However, initiating these incremental steps in pre-provisioning access to designated databases marks the initial move away from manually provisioning access for all database users with universal read-only privileges or, even worse, granting admin permissions to everyone. This transition represents the outset of a shift toward efficient and scalable just-in-time database management.
-
Oracle recently announced that the MySQL database server now supports JavaScript functions and procedures. JavaScript for stored routines is currently in preview and only available in the MySQL Enterprise Edition and MySQL Heatwave. The introduction of JavaScript support enables developers to implement advanced data processing logic within the database. By minimizing data movement between the database server and client applications, stored functions and procedures can reduce latencies, network overhead, and egress costs. Øystein Grøvlen, senior principal software engineer at Oracle, and Farhan Tauheed, consulting member of technical staff, write: Among the common use cases for the new feature, Oracle highlights data extraction, data formatting, approximate search, data validation, compression, encoding, and data transformation. Favorably received by the community, the announcement provides an example of a function where the JavaScript code is embedded directly in the SQL definition: CREATE FUNCTION gcd_js (a INT, b INT) RETURNS INT LANGUAGE JAVASCRIPT AS $$ let [x, y] = [Math.abs(a), Math.abs(b)]; while(y) [x, y] = [y, x % y]; return x; $$; Source: Oracle blog When the function is invoked using the traditional CALL statement, an implicit type conversion occurs between SQL types and JavaScript types. As per the documentation, JavaScript support is based on the ECMAScript 2021 standard, and all variations of integers, floating point, and CHAR/VARCHAR types are supported. Grøvlen and Tauheed add: The GraalVM run time includes JDK, language implementations (JavaScript, R, Python, Ruby, and Java), and a managed virtual machine with sandboxing capability and tooling support. While MySQL-JavaScript is available in the MySQL Enterprise Edition and MySQL Heatwave cloud service on OCI, AWS, and Azure, there is no support in the MySQL Community Edition. MySQL is not the first open-source relational database supporting Javascript in stored routines, with PLV8 being the most popular Javascript language extension for PostgreSQL. PLV8 is supported by all current releases of PostgreSQL, including managed services like Amazon RDS, and can be used for stored routines and triggers. Oracle has released three MySQL HeatWave videos on YouTube to demonstrate how to run the Mustache library, validate web form inputs, or process web URLs using stored programs in JavaScript.
-
Do you know that in some parts of the world, electronic invoices need to be preserved in an immutable form? Picture this: You issue an invoice, and it’s as untouchable as a museum artifact. But how do you keep it safe? Well, you could stash it in your database, but not just as plain old rows — they need fortification. Think PDFs snugly tucked within your database’s digital embrace. Now, here come the big decisions. Option one: You cram those PDFs into a BLOB or CLOB, making them feel cozy within a database row. Example of using a BLOB to store the file within a row in the database: CREATE TABLE invoices ( id SERIAL PRIMARY KEY, file_name VARCHAR(255) NOT NULL, file_data BLOB NOT NULL ); Option two: You let those files roam free on your file system while keeping a watchful eye on their metadata — names, locations, dates, and the like — stored safely in your database. Example of storing the file on the file system and recording the metadata in the database: CREATE TABLE invoices ( id SERIAL PRIMARY KEY, file_name VARCHAR(255) NOT NULL, file_path VARCHAR(255) NOT NULL, date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ); As to the great file-handling debate! When it comes to managing your electronic treasures, you’ve got options. For Go and Python, it’s as easy as pie — just reach for the ospackage. It’s like the Swiss Army knife of file handling, always ready to lend a helping hand. Meanwhile, over in Node land, they’ve got their trusty sidekick, fs, to tackle all things file-related. And let’s not forget about Rust, with its steadfast std::fs library by its side. It’s true that storing files in your database can be pricier than letting them loose on the file system, but sometimes you need that fortress-like protection. After all, keeping track of the integrity between your database and file system is like herding cats — way too complicated! In this end, just remember: when it comes to safeguarding your precious electronic documents, it’s all about finding the right balance between security and cost. And who said invoices couldn’t have a little adventure?
-
Google has awarded (https://foundation.rust-lang.org/news/google-contributes-1m-to-rust-foundation-to-support-c-rust-interop-initiative/) a million dollar grant to integrate Rust with its C++ products. The goal of the grant is to accelerate the adoption of Rust, not just at Google, but across the industry. Earlier (https://t.me/sysodmins/20862) Microsoft posted a software architect job posting that mentions (https://www.theregister.com/2024/01/31/microsoft_seeks_rust_developers/) the creation of a new development team to implement Rust and use it as the basis for modernizing globally scalable services.
-
The experts believe (https://www.theregister.com/2024/01/31/gpt4_gaelic_safety/?td=rt-4a) that they managed to bypass the GPT-4 security filters that prevent them from delivering "unsafe content". They translated the queries into rare languages and translated the answers back into English, and they looked quite convincing. ✍️ The scientists ran 520 unsafe requests through GPT-4 and found that they were able to bypass the protection 79% of the time. Simple translation was almost as successful at "cracking" the large language model as other, more sophisticated and technologically advanced methods. The model was more likely to fulfill queries related to terrorism, financial crimes, and misinformation. By the way, resource-limited languages are now spoken by about 1.2 billion people.
-
🥒 Pkl (pronounced Pickle) is an embedded language for configuration definition that provides (https://pkl-lang.org/blog/introducing-pkl.html) extensive support for templates and data validation. It can be used from the command line, integrated into the build pipeline, or embedded in applications. Pkl scales from small to large, from simple to complex, from ad hoc to repetitive configuration tasks. The associated Pkl toolkit is written in Kotlin and published under the Apache license. Plugins for working with Pkl code are prepared for IntelliJ, Visual Studio Code and Neovim development environments. The LSP (Language Server Protocol) handler is expected to be published soon. Pkl combines the properties of an easy-to-understand declarative language with advanced features typical for general-purpose languages. Pkl supports type annotations, classes, functions, computational expressions, conditions, and loops.
-
The project allows to create interactive web applications using C#, F#, XAML and .NET technologies. Silverlight applications compiled with OpenSilver can run in any desktop and mobile browsers with WebAssembly support, but compilation is still only possible in Windows using Visual Studio environment. In its current form, OpenSilver has already gone beyond a layer to extend the life of Silverlight and can be considered as an independent platform for creating new applications. For example, the project develops a development environment (an addition to Visual Studio), provides support for new versions of the C# language and the .NET platform, and provides compatibility with JavaScript libraries. OpenSilver uses the code of the open source projects Mono (mono-wasm) and Microsoft Blazor (part of ASP.NET Core) as a basis, and compilation of applications into WebAssembly intermediate code is used for execution in the browser. https://www.opensilver.net/
-
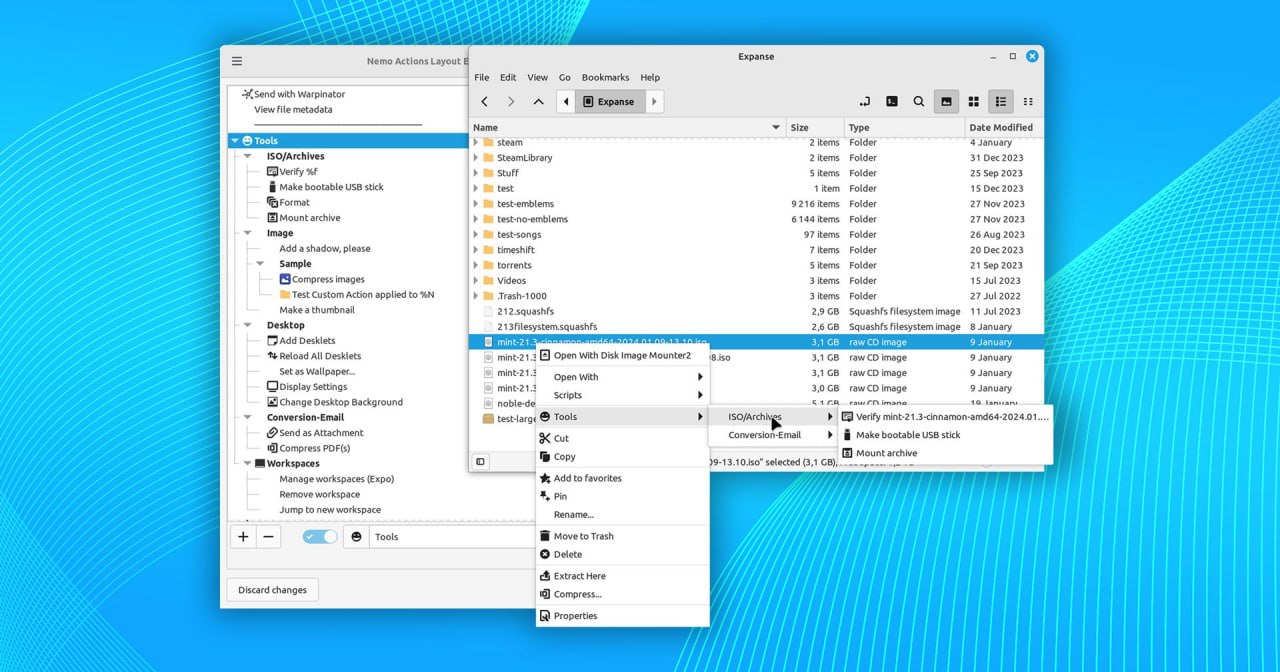
▪️ The code name for Linux Mint 22 is 'Wilma'. Mint uses many female names starting with W in point releases, including Wendy, Winona, Wanda, Winnie and Winifred. ▪️ Linux Mint 22 is based on Ubuntu 24.04. Although this framework has not yet been implemented (the release is not expected until April), Mint will inherit many of its changes. It will most likely include the Linux 6.8 kernel by default, rather than Linux 6.6 LTS. ▪️ New feature for the Cinnamon desktop: the 'Nemo Actions Organizer' application. Nemo Actions allows users to add additional actions to the right-click context menu in the Nemo file manager, such as 'open folder in terminal', 'run ISO checksum', 'compress PDF', etc. https://www.omgubuntu.co.uk/2024/01/linux-mint-22-codename-revealed
-
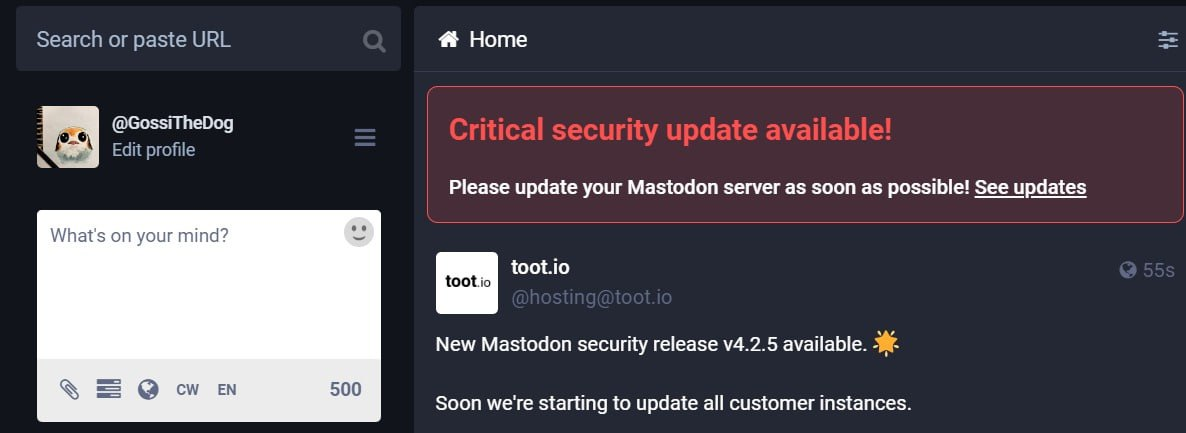
A critical vulnerability (https://github.com/mastodon/mastodon/security/advisories/GHSA-3fjr-858r-92rw) (CVE-2024-23832) has been patched in the code of Mastodon, an opt-in decentralized decentralized social network, which allowed attackers to impersonate and take over any account. No details have been disclosed yet, only a call to upgrade to version 4.2.5.
-
-
Intel has released (https://lore.kernel.org/lkml/[email protected]/) a series of patches for Thread Director thread scheduler in Linux. Updates for virtualization technology improve the performance of virtual machines running on Intel hybrid platforms and modern processors (with P and E cores) from 3% to 14% (depending on the task at hand). The patches can help improve the performance of Linux-based systems that are used to run games on a Windows client virtual machine as a cloud gaming solution. The goal of the new patch set is to enable ITD-based scheduling logic in the guest system to better schedule tasks on Intel's hybrid platforms. The Intel team continues to refine support for Intel Thread Director virtualization in Linux and it is likely that these patches will be included in new versions of Linux kernels to improve performance with Intel Core hybrid processors.
-
KaOS 2024.01 (https://kaosx.us/) is a distribution with a continuous update model, aimed at providing a desktop based on recent releases of KDE and applications using Qt. Among the distribution-specific design features is the placement of a vertical panel on the right side of the screen. The distribution is inspired by Arch Linux, but maintains its own independent repository of over 1500 packages and offers a number of its own graphical utilities.
-
-
The Kubuntu Linux developers have announced (https://kubuntu.org/news/kubuntu-council-meeting-30th-january-2024/) work to migrate the distribution to use the Calamares installer. Calamares is independent of specific Linux distributions and uses the Qt library to create the user interface. Using Calamares will enable a single graphics stack in a KDE-based environment. Lubuntu and UbuntuDDE have previously adopted the Calamares installer from official Ubuntu editions.
-
The developers have published (https://lists.debian.org/debian-devel-announce/2024/02/msg00000.html) a plan to convert all packages to use the 64-bit time_t type in distribution ports for 32-bit architectures. The changes will be part of the Debian 13 "Trixie" distribution, which will fully address the 2038 issue. Of the 35960 packages shipped in Debian, the time_t type occurs in 6429 and affects over 1200 libraries. Once the experimental branch has resolved all post-translation issues, new variants of the "abi=time64" libraries will be uploaded to the unstable repository.
-
-
Developers are building (https://www.gentoo.org/news/2024/02/04/x86-64-v3.html) a separate repository with binary packages built to support the third version of the x86-64 microarchitecture (x86-64-v3), which has been used in Intel processors since about 2015 (starting with Intel Haswell). It is distinguished by the presence of extensions such as AVX, AVX2, BMI2, FMA, LZCNT, MOVBE, and SXSAVE. The repository offers a separate set of packages formed in parallel with the repository published in December, which builds for the basic x86-64 architecture, which can be used on any 64-bit Intel and AMD processors.
-
1. How would you diagnose a Linux system that’s unresponsive to user input? Diagnosing an unresponsive Linux system requires a systematic approach: First, check if the system responds to keyboard shortcuts, such as CTRL+ALT+F1, to switch to a different terminal. If that doesn't work, try accessing the system remotely using Secure Shell Protocol (SSH). If you can access the system, review the system logs in /var/log/messages and use commands like top to see if any specific process is causing the unresponsiveness. Check the system's memory using free -m to identify if it's a memory issue. If you suspect hardware issues, you can check hardware logs and diagnostic tools. When everything else fails, a forced reboot may be necessary, but it should be the last resort. You should carefully note the symptoms and messages if the issue recurs, as this information could help with future diagnoses. 2. Describe how you would approach resolving a “disk full” error on a Linux system. Resolving a “disk full” error on a Linux system involves identifying what’s taking up space and freeing that space up. Here's how you could approach it: Identify the disk usage: Use the df command to check overall disk space and du to find the directories consuming most of the space. Locate unnecessary files: Use commands like find to locate old or unnecessary files, such as logs or temporary files. Clear cache and temporary files using appropriate commands or tools. Evaluate log files and consider implementing log rotation if it’s not already in place. Uninstall unneeded packages or software. Check for core dumps that can be deleted. Verify trash: Empty the user's trash bin if necessary. Expand disk if necessary: Consider expanding the disk or partition if the issue recurs frequently. 3. Explain the steps you'd take to troubleshoot a network connectivity issue on a Linux server. Troubleshooting network connectivity on a Linux server involves several steps: Start by verifying the physical connections if you have access to them. Proceed to examining the network configuration using commands like ifconfig or ip addr. Check if the network interface is up and has the correct internet protocol (IP) address. Next, test the connectivity to the local network with ping and inspect routing with route -n or ip route. Verify the domain name system (DNS) configuration in /etc/resolv.conf and test DNS resolution. If a firewall is present, review the rules to ensure it's not blocking the necessary traffic. Analyze the output of the netstat command to reveal potential issues with listening ports. Lastly, review system and network logs found in /var/log, which might give clues to specific issues. 4. On Linux, how can you check the status of a service and restart it if it's not running? To check service status and restart the service if necessary, you can: Use systemctl status serviceName to check the status of a specific service. Look at the output and identify if the service is active or inactive. If the service isn’t running, use systemctl restart serviceName to restart it. Run systemctl status serviceName again to ensure the service is active and running properly. If you want the service to start automatically at boot, use systemctl enable serviceName. This approach ensures that services essential for the system's functionality are always active. 5. What could be the reasons for a sudden increase in central processing unit (CPU) utilization on a Linux server? How would you identify the culprit process? A sudden spike in CPU utilization on a Linux server could have multiple causes. For example, it might be due to a rogue process consuming excessive resources, a poorly optimized script or application, a sudden increase in user activity, or even a malware attack. To identify the culprit, you could use the top or htop commands, which display real-time system statistics and highlight the processes consuming the most CPU. You can then analyze the specific process to understand its behavior. Running the ps command with specific flags can give detailed insights into processes. Analyzing log files may also provide clues if the spike is related to specific scheduled tasks or application behaviors. You should handle the diagnosis carefully to optimize the server’s performance without affecting crucial processes or user experience. 6. What Linux commands would you use to diagnose a slow server response time? Diagnosing a slow server response time on a Linux system involves using several commands to identify the bottleneck. Here's a step-by-step guide: Monitor system resources. Use top or htop to monitor CPU and memory usage. Analyze disk input/output (I/O). Use iostat to check if disk input/output is a bottleneck. Inspect network traffic. Use iftop or nethogs to examine network traffic and look for unusual activities. Check server load. Use uptime to review the server load and compare it with the number of available CPU cores. Evaluate running processes. Use ps with proper flags to view and analyze the running processes. Review logs. Inspect log files in /var/log for error messages or warnings. Profile application. If an application is slow, use profiling tools specific to the application or language. With these commands, you can pinpoint the root cause of the slow server response time and take appropriate actions to enhance performance. 7. How can you determine which process is consuming the most memory on a Linux system? You can identify the processes that are using the most memory on a Linux system by using the following steps: Open the terminal. Type the command top and press Enter. This command shows an overview of all active processes. Look for the column labeled “%MEM”. This shows the percentage of total system memory being used by each process. Identify the process consuming the most memory by checking the highest percentage in the “%MEM” column. Another option is to use the ps command with specific options, like ps aux --sort=-%mem | head -n 10. This command sorts the processes by memory usage, displaying the ten processes using the most memory. 8. Describe the steps you'd take to diagnose and mitigate a security breach on a Linux server. The first step is to isolate the affected system from the network to prevent the breach from spreading. You analyze the logs to understand the nature and source of the breach using tools like fail2ban or aide. Identifying compromised files and users is crucial. Next, you remove malicious files and close any vulnerabilities, which might require patching the system or updating software. In some cases, a complete system rebuild might be necessary. Continuous monitoring is essential to ensure that the issue is entirely resolved. 9. Describe how you'd troubleshoot a situation where a user cannot log in to a Linux system. When a user is struggling to log in to a Linux system, you can: Verify the user's username and password. Ensure the user is using the correct credentials. Check if the user account is locked. Use the passwd -S username command to see the account status. Inspect the permissions of the user's home directory. The permissions must allow the user to read and write. Examine system logs. Look at the /var/log/auth.log file for error messages related to the login issue. If you’re using SSH for remote login, check the SSH configuration file for any restrictions on the user's access. Following these steps can identify and fix the login problem's root cause, ensuring smooth access to the Linux system for the user. 10. What could cause intermittent SSH connection failures, and how would you investigate them? Intermittent SSH connection failures can be a complex issue to diagnose. They may stem from various causes, like network issues, server overload, or configuration errors. Here's how you'd investigate: Check the network. Verify the network connection between the client and server is stable. Use ping to check if the server is reachable. Examine the server load. If the server is overloaded, it might refuse new connections. Use commands like top to monitor the server's performance. Look at the SSH configuration. Check the SSH configuration file /etc/ssh/sshd_config for any incorrect settings that might be causing the failure. Review the logs. Inspect the server's SSH log files, usually found in /var/log/auth.log, for specific error messages. Test with different clients. If possible, attempt to connect from a different client machine to isolate the issue. Investigating these areas will help identify the underlying cause of the intermittent failures and lead to a resolution, ensuring reliable remote access to the Linux system. 11. How would you diagnose and fix the time synchronization problem if a server's clock is consistently incorrect? A Linux server clock that’s consistently wrong might indicate a time synchronization problem. To diagnose this, you can check the system's connection to a network time protocol (NTP) server. Tools like timedatectl or ntpq can help you analyze the synchronization status. If you find the NTP servers are misconfigured, you can reconfigure the NTP daemon by editing the /etc/ntp.conf file and selecting the right NTP servers. Restarting the NTP service will then synchronize the server's clock. You should conduct regular monitoring to ensure that the problem doesn't recur. 12. What steps would you take to identify and resolve the issue in which a Linux system fails to boot? You can diagnose a non-booting Linux system by employing these steps: Check the boot loader. Start by ensuring the boot loader (such as GRUB) is properly configured. Access recovery mode. Reboot the system into recovery mode to access command-line tools. Examine the log files. Check logs like /var/log/syslog to find error messages. Inspect the kernel messages. Use the dmesg command to see kernel-related issues. Test the hardware. Check for hardware failure using tools like smartctl. Perform a file system check. Run fsck on disk partitions to repair corrupted file systems. Reinstall packages. Reinstall necessary packages or update them if they're causing the issue. 13. How can you determine if a specific port is open and reachable on a remote Linux server? To determine if a specific port is open and reachable on a remote Linux server, you'd use tools like telnet, nc (netcat), or nmap. You can check if the port is reachable by running commands like telnet hostname portnumber or nc -zv hostname portnumber. For a more comprehensive scan, you can use nmap to find extensive details about open ports and their corresponding services. Be sure you have proper authorization, as scanning without permission might be considered hostile. 14. How can you diagnose and address issues related to DNS resolution on a Linux machine? DNS resolution issues can disrupt network connectivity. Here’s how to diagnose and address them: Check the connection. Ensure network connectivity using commands like ping. Inspect the DNS configuration. View the /etc/resolv.conf file to see the DNS servers. Use diagnostic tools. Tools like nslookup or dig can diagnose DNS queries. Restart the DNS service. Refreshing the DNS service using systemctl restart may fix problems. Flush the DNS cache. Clear the DNS cache with systemd-resolve --flush-caches, which can resolve some conflicts. Consult system logs. Look at logs like /var/log/syslog for detailed error information. 15. Explain the concept of file permissions on a Linux system, and describe how incorrect permissions can lead to issues. File permissions in Linux govern who can read, write, and execute a file. There are three types of permissions: user (owner), group, and others. You can view permissions using the ls -l command and modified with the chmod command. Incorrect permissions can lead to various problems. For example, setting a file to be readable by anyone might expose sensitive information, while unrestricted writability could enable others to modify it unnecessarily. Ultimately, incorrect execution permissions can lead to software malfunctions. 16. Describe the significance of log files in troubleshooting, and provide examples of important log files on a Linux system. Log files are essential for troubleshooting as they record system activities and errors. You can use them for: Tracking errors. Log files record failures and issues, helping diagnose issues. Security monitoring. They help monitor unauthorized access attempts. Performance analysis. They can reveal system performance issues. Some important log files on a Linux system include: /var/log/syslog: General system activities and errors. /var/log/auth.log: Authentication logs, including successful and failed login attempts. /var/log/kern.log: Kernel logs, which are helpful in diagnosing hardware-related problems. /var/log/dmesg: Boot and kernel messages. 17. What is a kernel panic, and how would you troubleshoot it on a Linux system? A kernel panic is a critical error in the Linux system's kernel that causes the operating system to stop abruptly. It’s like a blue screen error in Windows and indicates an unrecoverable condition. Troubleshooting a kernel panic involves the following steps: Reboot the system. Simply restart the system, which sometimes solves the issue. Analyze the error message. Note the error message displayed during the panic for further investigation. Check log files. Look into /var/log/kern.log or /var/log/messages to identify specific problems. Update the system. Make sure all software, including the kernel, is up to date. Test hardware. Run diagnostics to rule out faulty components. 18. Describe the steps you'd take to troubleshoot a situation where a user can't access a specific website from a Linux machine. Troubleshooting access to a website on a Linux machine requires several steps: First, verify whether the issue is limited to the specific website by trying to access other websites. Next, use the ping command to check network connectivity. If network connectivity is fine, use the nslookup or dig commands to diagnose any DNS issues. If the DNS isn’t the problem, inspect the local firewall rules and proxy settings. Examine browser-related issues by checking for error messages or trying a different browser. Examine the /etc/hosts file to see if the site is inadvertently blocked as an alternative solution. 19. Explain the purpose of the strace command and how it can assist in diagnosing problems. The strace command in Linux is a powerful tool used to trace a particular program's system calls and signals. It helps diagnose issues by providing detailed information about how a program interacts with the operating system. Here's how you can use it: Identify errors. Run strace followed by a command to see where a program might be failing. Analyze performance. Detect where bottlenecks or performance issues occur within the application. Debug issues. Uncover unexpected behaviors in programs by using the command to display the sequence of system calls. Improve understanding. Gain insights into how programs work and interact with the Linux system (this is especially useful for developers). Trace specific activities. Filter specific system calls or files to narrow down the diagnosis. 20. If a user complains about slow file access, what tools and techniques would you use to identify the cause? Here are tools and techniques for diagnosing the issue: Ask specific questions. Find out which types of files are affected and when the problem started. Use diagnostic tools. Use commands like iotop, vmstat, or iostat to monitor I/O activities. Check disk usage. Ensure the disk isn't full using the df and du commands. Analyze network performance. If files are on a network, use tools like ping and traceroute to determine if network latency is the issue. Review user permissions. Ensure the user has appropriate permissions to access the files. Consult log files. Review system logs for any related errors or warnings. Evaluate disk health. Perform disk checks to ensure no hardware issues are contributing to the problem. Slow file access can affect productivity, so identifying the cause is vital for a smooth workflow. How to assess Linux administrators’ troubleshooting skills While you can use the interview questions above to gain insight into a candidate's Linux troubleshooting knowledge, interviews should serve as only one part of your assessment.
-
▪️ What is the difference between Linux and Unix? The answer is in the picture. And some other differences: Linux is a clone of Unix. But if you consider the Portable Operating System Interface Standards (POSIX), Linux can be considered as UNIX. - Linux is just a kernel All Linux distributions include a GUI system, GNU utilities, installation and management tools, GNU c / c ++ compilers, editors (vi) and various applications such as OpenOffice, Firefox. UNIX operating systems are considered a complete operating system because everything comes from a single vendor. - Security and firewall Linux comes with open source Netfilter and an IPTables based firewall to protect your server and desktop from intruders and hackers. UNIX operating systems come with their own firewalls. - Backup and Restore UNIX and Linux come with their own set of tools for backing up data to tape and other backup media. However, both Linux and UNIX have some common tools such as tar, dump/restore, cpio, etc.